

In probability theory, the central limit theorem (CLT) states that the distribution of a sample variable approximates a normal distribution (i.e., a “bell curve”) as the sample size becomes larger, assuming that all samples are identical in size, and regardless of the population’s actual distribution shape.
Put another way, CLT is a statistical premise that, given a sufficiently large sample size from a population with a finite level of variance, the mean of all sampled variables from the same population will be approximately equal to the mean of the whole population. Furthermore, these samples approximate a normal distribution, with their variances being approximately equal to the variance of the population as the sample size gets larger, according to the law of large numbers.
The concept of a Brownian motion was discovered when Einstein observed particles oscillating in liquid. Since fluid dynamics are so chaotic and rapid at the molecular level, this process can be modelled best by assuming the particles move randomly and independently of their past motion. We can also think of Brownian motion as the limit of a random walk as its time and space increments shrink to 0. In addition to its physical importance,
Brownian motion is a central concept in stochastic calculus.
A standard (one-dimensional) Wiener process (also called Brownian motion) is a stochastic process  indexed by nonnegative real numbers t with the following properties:
indexed by nonnegative real numbers t with the following properties:
 = 0. has stationary, independent increments.
= 0. has stationary, independent increments. has the
has the  distribution.
distribution.One of the many reasons that Brownian motion is important in probability theory is that it is, in a certain sense, a limit of rescaled simple random walks. Let  be a sequence of independent, identically distributed random variables with mean 0 and variance 1. For each
be a sequence of independent, identically distributed random variables with mean 0 and variance 1. For each  define a continuous-time stochastic process
define a continuous-time stochastic process  by:
by:

This is a random step function with jumps of size  at times
at times  , where
, where  . Since the random variables
. Since the random variables  are independent, the increments of
are independent, the increments of  are independent. Moreover, for large n the distribution of
are independent. Moreover, for large n the distribution of  is close to the distribution, by the Central Limit theorem. Thus, it requires only a small leap of faith to believe that, as
is close to the distribution, by the Central Limit theorem. Thus, it requires only a small leap of faith to believe that, as  , the distribution of the random function
, the distribution of the random function  approaches (in a sense made precise below) that of a standard Brownian motion.
approaches (in a sense made precise below) that of a standard Brownian motion.
Why is this important? First, it explains, at least in part, why the Wiener process arises so commonly in nature. Many stochastic processes behave, at least for long stretches of time, like random walks with small but frequent jumps. The argument above suggests that such processes will look, at least approximately, and on the appropriate time scale, like Brownian motion.
Second, it suggests that many important “statistics” of the random walk will have limiting distributions and that the limiting distributions will be the distributions of the corresponding statistics of Brownian motion. The simplest instance of this principle is the central limit theorem: the distribution of  is, for large n close to that of
is, for large n close to that of  (the gaussian distribution with mean 0 and variance 1). Other important instances do not follow so easily from the central limit theorem. For example, the distribution of:
(the gaussian distribution with mean 0 and variance 1). Other important instances do not follow so easily from the central limit theorem. For example, the distribution of:

converges, as , to that of:

In probability theory, Donsker’s theorem (also known as Donsker’s invariance principle, or the functional central limit theorem), named after Monroe D. Donsker, is a functional extension of the central limit theorem.
Let be a sequence of independent and identically distributed (i.i.d.) random variables with mean 0 and variance 1.
Let .
The stochastic process is known as a random walk. Define the diffusively rescaled random walk (partial-sum process) by
The central limit theorem asserts that converges in distribution to a standard Gaussian random variable as . Donsker’s invariance principle extends this convergence to the whole function . More precisely, in its modern form, Donsker’s invariance principle states that: As random variables taking values in the Skorokhod space* , the random function converges in distribution to a standard Brownian motion as .
*The set of all càdlàg functions from E to M is often denoted by D(E; M) (or simply D) and is called Skorokhod space after the Ukrainian mathematician Anatoliy Skorokhod.

12_R.What is the “Brownian motion” and what is a Wiener process. History, importance, definition and applications (Bachelier, Wiener, Einstein, …).
13_R. An “analog” of the CLT for stochastic process: the standard Wiener process as “scaling limit” of a random walk and the functional CLT (Donsker theorem) or invariance principle. Explain the intuitive meaning of this result and how you have already illustrated the result in your homework.
12_A. Discover one of the most important stochastic process by yourself!
Consider the general scheme we have used so far to simulate stochastic processes (such as the relative frequency of success in a sequence of trials, the sample mean, the random walk, the Poisson point process, etc.) and now add this new process to our simulator.
Starting from value 0 at time 0, for each of m paths, at each new time compute P(t) = P(t-1) + Random step(t), for t = 1, …, n,
where the Random step(t) is now:
σ * sqrt(1/n) * Z(t),
where Z(t) is a N(0,1) random variable (the “diffusion” σ is a user parameter, to scale the process dispersion).
At time n (last time) and one (or more) other chosen inner time 1.
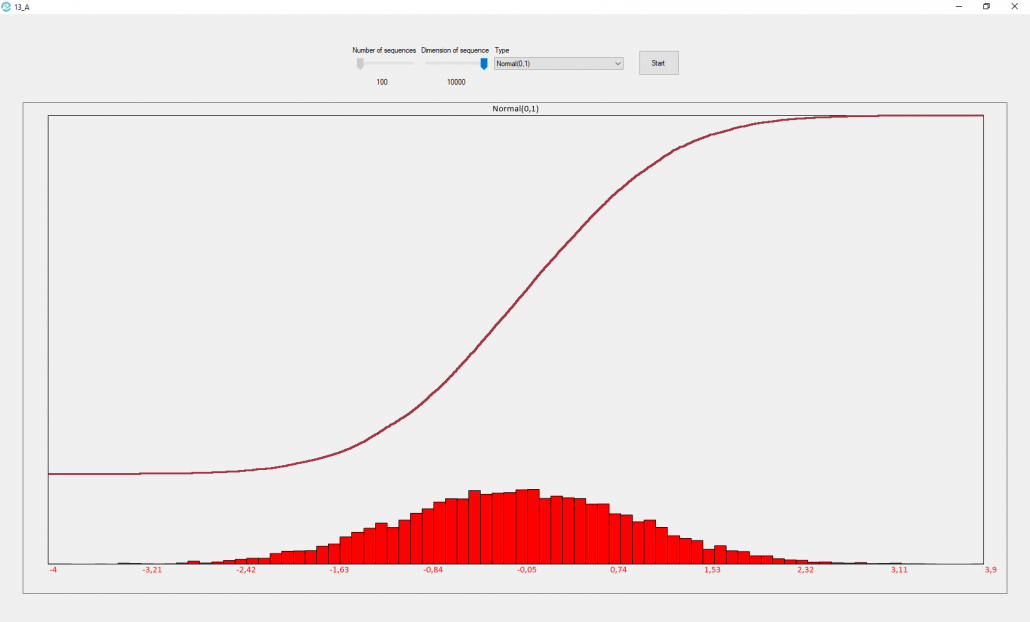
13_A. Create the a distribution representation (histogram, or CDF …) to represent the following:
– Realizations taken from a Normal(0,1)
– Realizations of the mean, obtained by averaging several times (say m times, m large) n of the above realizations
– Realizations of the variance, obtained by averaging several times (say m times, m large) n of the above realizations
– Realizations taken from exp(N(0,1)))
– Realizations taken from N(0,1) squared
– Realizations taken from a (squared N(0,1)) divided by another (squared N(0,1)).
9_RA Try to find on the web what are the names of the random variables that you just simulated in the applications, and see if the means and variances that you obtain in the simulation are compatible with the “theory”. If not fix the possible bugs.

The concept of a Brownian motion was discovered when Einstein observed particles oscillating in liquid. Since fluid dynamics are so chaotic and rapid at the molecular level, this process can be modeled best by assuming the particles move randomly and independently of their past motion. We can also think of Brownian motion as the limit of a random walk as its time and space increments shrink to 0. In addition to its physical importance, Brownian motion is a central concept in stochastic calculus which can be used in finance and economics to model stock prices and interest rates.
Much of probability theory is devoted to describing the macroscopic picture emerging in random systems defined by a host of microscopic random effects. Brownian motion is the macroscopic picture emerging from a particle moving randomly in d-dimensional space without making very big jumps. On the microscopic level, at any time step, the particle receives a random displacement, caused for example by other particles hitting it or by an external force, so that, if its position at time zero is  , its position at time n is given as
, its position at time n is given as  , where the displacements
, where the displacements  are assumed to be independent, identically distributed random variables with values in
are assumed to be independent, identically distributed random variables with values in  . The process
. The process  is a random walk, the displacements represent the microscopic inputs. It turns out that not all the features of the microscopic inputs contribute to the macroscopic picture. Indeed, if they exist, only the mean and covariance of the displacements are shaping the picture. In other words, all random walks whose displacements have the same mean and covariance matrix give rise to the same macroscopic process, and even the assumption that the displacements have to be independent and identically distributed can be substantially relaxed. This effect is called universality, and the macroscopic process is often called a universal object. It is a common approach in probability to study various phenomena through the associated universal objects.
is a random walk, the displacements represent the microscopic inputs. It turns out that not all the features of the microscopic inputs contribute to the macroscopic picture. Indeed, if they exist, only the mean and covariance of the displacements are shaping the picture. In other words, all random walks whose displacements have the same mean and covariance matrix give rise to the same macroscopic process, and even the assumption that the displacements have to be independent and identically distributed can be substantially relaxed. This effect is called universality, and the macroscopic process is often called a universal object. It is a common approach in probability to study various phenomena through the associated universal objects.
If the jumps of a random walk are sufficiently tame to become negligible in the macroscopic picture, in particular if it has finite mean and variance, any continuous time stochastic process  describing the macroscopic features of this random walk should have the following properties:
describing the macroscopic features of this random walk should have the following properties:
 the random variables
the random variables  are independent; we say that the process has independent increments,
are independent; we say that the process has independent increments, does not depend on
does not depend on  ; we say that the process has stationary increments, has almost surely continuous paths.
; we say that the process has stationary increments, has almost surely continuous paths. and
and  the increment is multivariate normally distributed with mean
the increment is multivariate normally distributed with mean  and covariance matrix
and covariance matrix  .
.Hence any process with the features (1)-(3) above is characterised by just three parameters,
 ,
, ,
, .
.If the drift vector is zero, and the diffusion matrix is the identity we say the process is a Brownian motion. If  , i.e. the motion is started at the origin, we use the term standard Brownian motion.
, i.e. the motion is started at the origin, we use the term standard Brownian motion.
Suppose we have a standard Brownian motion . If  is a random variable with values in and a
is a random variable with values in and a  matrix, then it is easy to check that
matrix, then it is easy to check that  given by
given by
 , for ,
, for ,
is a process with the properties (1)-(4) with initial distribution , drift vestor and diffusion matrix . Hence the macroscopic picture emerging from a random walk with finite variance can be fully described by a standard Brownian motion.

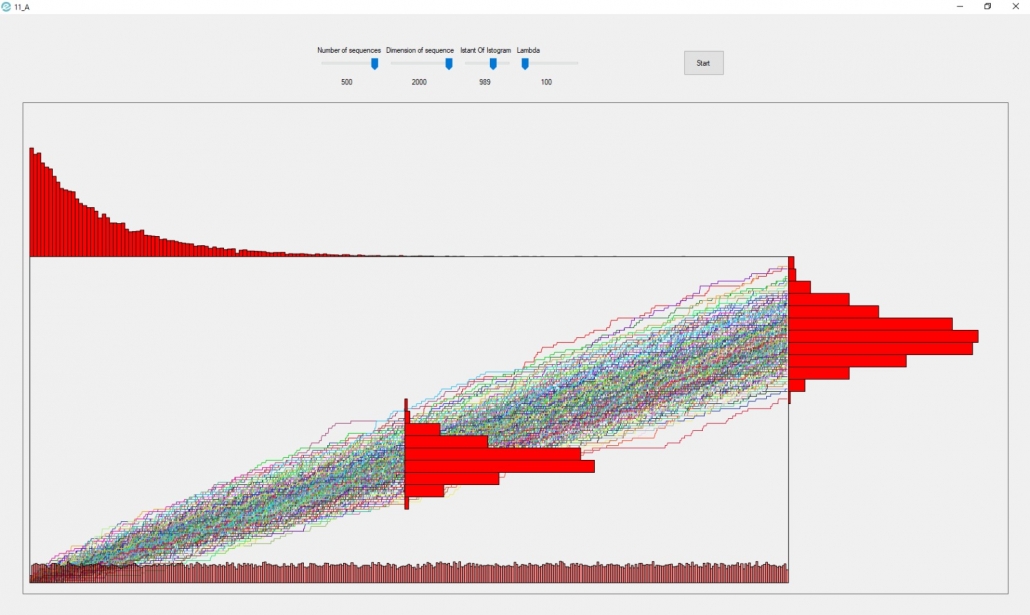
The previous graph is taken from application 11_A, as we can see the following distributions are present:
A Poisson process is a model for a series of discrete events where the mean time between events is known, but the exact timing of the events is random. The arrival of an event is independent of the previous event. The important point is that we know the mean time between events but they are randomly spaced (stochastic). We could have consecutive failures, but we could also spend years between failures due to the randomness of the process.
A Poisson process satisfies the following criteria (in reality many phenomena modeled as Poisson processes do not exactly satisfy them):
Poisson distribution
The Poisson process is the model we use to describe randomly occurring events. Using the Poisson Distribution we could find the probability of a number of events over a period of time or find the probability of waiting some time until the next event.
The probability function of the Poisson distribution gives the probability of observing k events over a period of time given the length of the period and the time-averaged events:

This is a little convoluted, and events/time * time period is usually simplified into a single parameter, λ, lambda, the rate parameter. With this substitution, the Poisson Distribution probability function now has one parameter:

Lambda can be thought of as the expected number of events in the interval.
When we change the parameter λ we change the probability of seeing different numbers of events in an interval. The graph below is the probability mass function of the Poisson distribution which shows the probability of a number of events occurring in an interval with different velocity parameters.
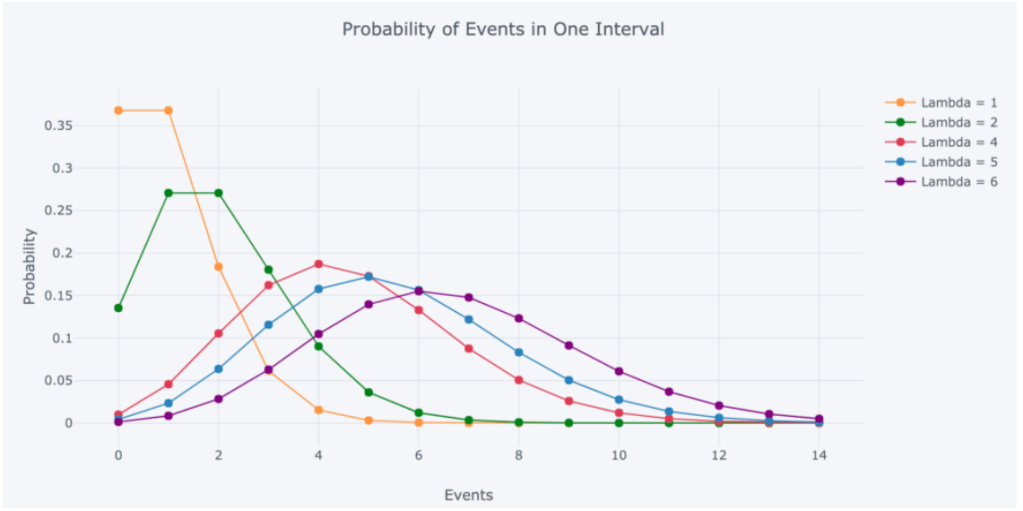
The Poisson Distribution and Poisson Process Explained | by Will Koehrsen | Towards Data Science
Order statistics are a very useful concept in statistical sciences. They have a wide range of applications including modelling auctions, car races, and insurance policies, optimizing production processes, estimating parameters of distributions, and so forth.
Suppose we have a set of random variables X1, X2, …, Xn, which are independent and identically distributed (i.i.d). By independence, we mean that the value taken by a random variable is not influenced by the values taken by other random variables. By identical distribution, we mean that the probability density function (PDF) (or equivalently, the Cumulative distribution function, CDF) for the random variables is the same. The kth order statistic for this set of random variables is defined as the kth smallest value of the sample.
To better understand this concept, we’ll take 5 random variables X1, X2, X3, X4, X5. We’ll observe a random realization/outcome from the distribution of each of these random variables. Suppose we get the following values:
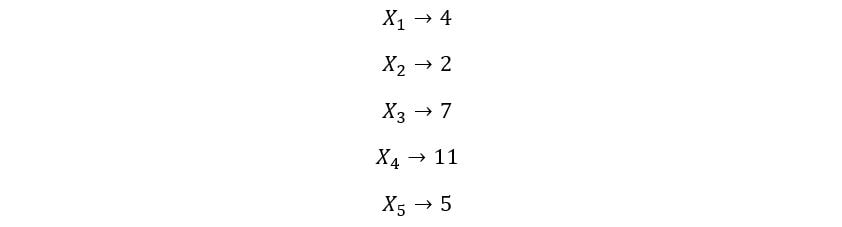
The kth order statistic for this experiment is the kth smallest value from the set {4, 2, 7, 11, 5}. So, the 1st order statistic is 2 (smallest value), the 2nd order statistic is 4 (next smallest), and so on. The 5th order statistic is the fifth smallest value (the largest value), which is 11. We repeat this process many times i.e., we draw samples from the distribution of each of these i.i.d random variables, & find the kth smallest value for each set of observations. The probability distribution of these values gives the distribution of the kth order statistics.
In general, if we arrange random variables X1, X2, …, Xn in ascending order, then the kth order statistic is shown as:

The general notation of the kth order statistic is X(k). Note X(k) is different from Xk. Xk is the kth random variable from our set, whereas X(k) is the kth order statistic from our set. X(k) takes the value of Xk if Xk is the kth random variable when the realizations are arranged in ascending order.
The 1st order statistic X(1) is the set of the minimum values from the realization of the set of ‘n’ random variables. The nth order statistic X(n) is the set of the maximum values (nth minimum values) from the realization of the set of ‘n’ random variables. They can be expressed as:
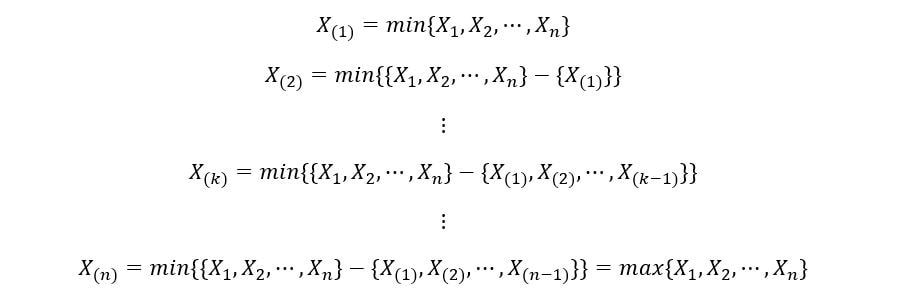
We’ll now try to find out the distribution of order statistics. We’ll first describe the distribution of the nth order statistic, then the 1st order statistic & finally the kth order statistic in general.
Let the probability density function (PDF) & cumulative distribution function (CDF) our random variables be fx(x), and Fx(x) respectively. By definition of CDF,
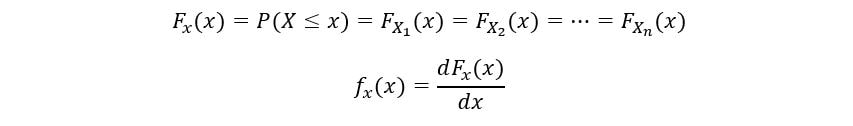
Since our random variables are identically distributed, they have the same PDF fx(x) & CDF Fx(x). We’ll now calculate the CDF of nth order statistic (Fn(x)) as follows:
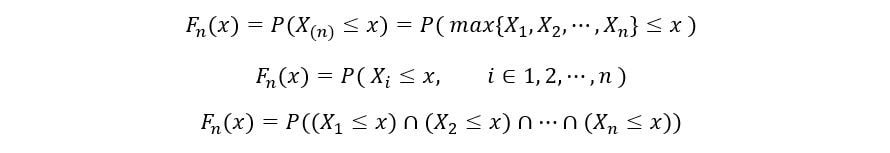
The random variables X1, X2, …, Xn are also independent. Therefore, by property of independence,
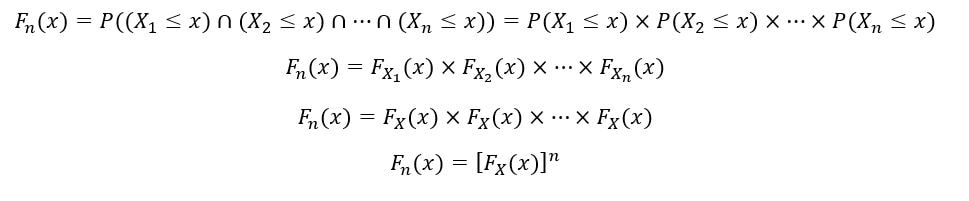
The PDF of the nth order statistic (fn(x)) is calculated as follows:
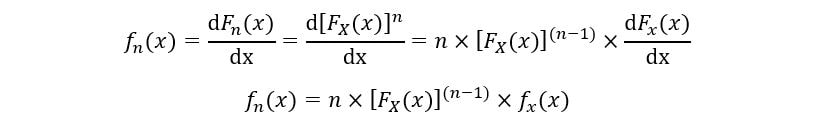
Thus, the expression for the PDF & CDF of nth order statistic has been obtained.
The CDF of a random variable can also be calculated as the one minus the probability that the random variable X takes a value more than or equal to x. Mathematically,
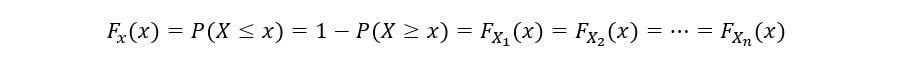
We’ll determine the CDF of 1st order statistic (F1(x)) as follows:
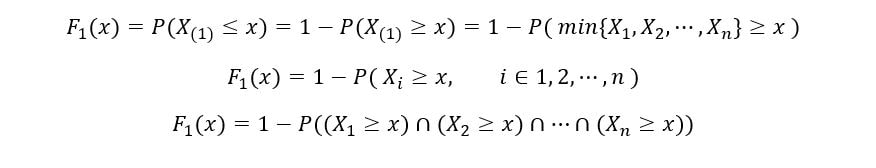
Once again, using the property of independence of random variables,
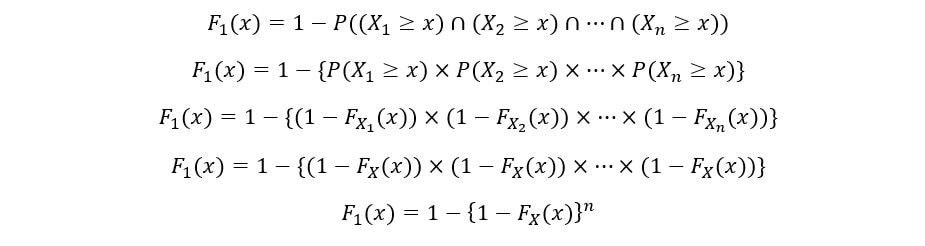
The PDF of the 1st order statistic (f1(x)) is calculated as follows:
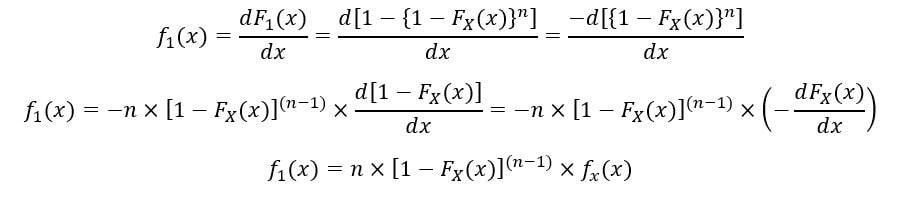
Thus, the expression for PDF & CDF of 1st order statistic has been obtained.
For kth order statistic, in general, the following equation describes its CDF (Fk(x)):
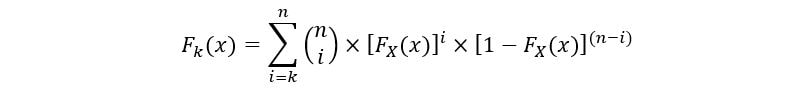
The PDF of kth order statistic (fk(x)) is expressed as:
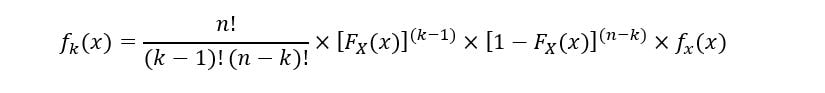
To avoid confusion, we’ll use geometric proof to understand the equation. As discussed before, the set of random variables have the same PDF (fX(x)). The following graph shows a sample PDF with the kth order statistic obtained from random sampling:
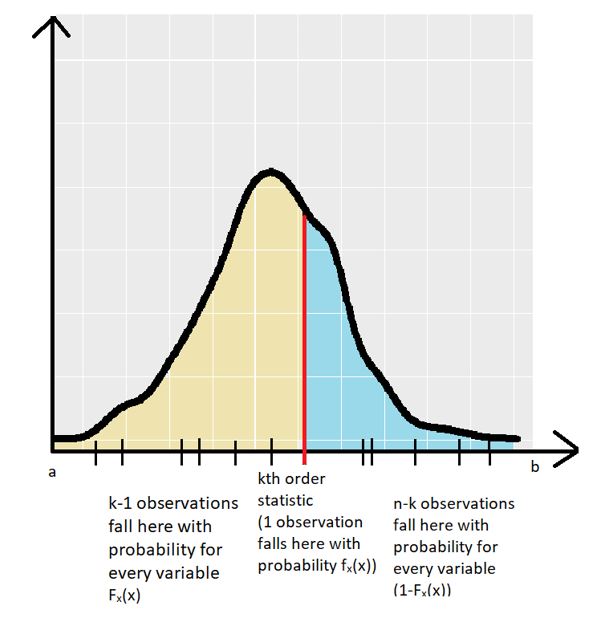
So, the PDF of the random variables fX(x) is defined between the interval [a,b]. The kth order statistic for a random sample is shown by the red line. The other variable realizations (for the random sample) are shown by the small black lines on the x-axis.
There are exactly (k – 1) random variable observations that fall in the yellow region of the graph (the region between a & kth order statistic). The probability that a particular observation falls in this region is given by the CDF of the random variables (FX(x)). But we are aware that (k – 1) observations did fall in the region, which gives us the term (by independence) (FX(x))(k – 1).
There are exactly (n – k) random variable observations that fall in the blue region of the graph (the region between kth order statistic & b). The probability that a particular observation falls in this region is given by the 1 – CDF of the random variables (1– FX(x)). But we are aware that (n – k) observations did fall in the region, which gives us the term (by independence) (1–FX(x))(n – k).
Finally, exactly 1 observation falls exactly at the kth order statistic with probability fX(x). Thus, the product of the 3 terms gives us an idea of the geometric meaning of the equation for PDF of the kth order statistic. But where does the factorial term come from? The above scenario just showed one of the many orderings. There can be many such combinations. The total number of such combinations is shown as follows:
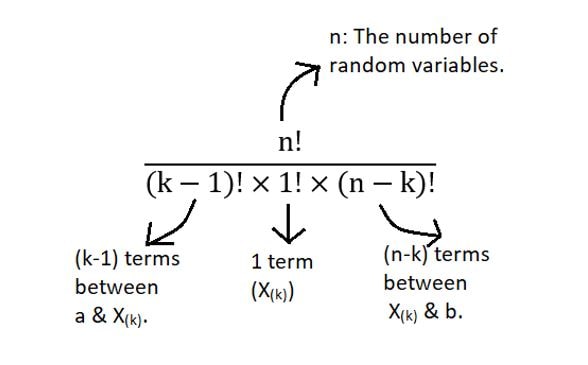
Thus, the product of all of these terms gives us the general distribution of the kth order statistic.
Order statistics give rise to various useful functions. Among them, the notable ones include sample range and sample median.
1) Sample range: It is defined as the difference between the largest and smallest value. It is expressed as follows:
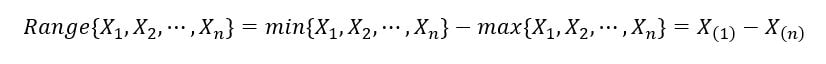
2) Sample median: The sample median divides the random sample (realizations from the set of random variables) into two halves, one that contains samples with lower values, and the other that contains the samples with higher values. It’s like the middle/central order statistic. It is mathematically defined as:
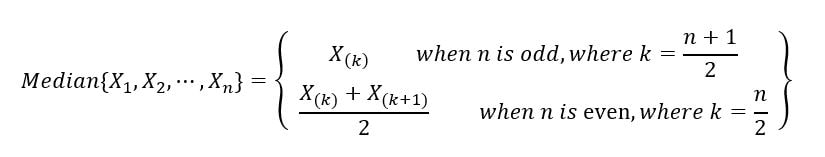
A joint probability density function can help us better understand the relationship between two random variables (two order statistics in our case). The joint PDF for any 2 order statistics X(a) & X(b), such that 1 ≤ a ≤ b ≤ n is given by the following equation:
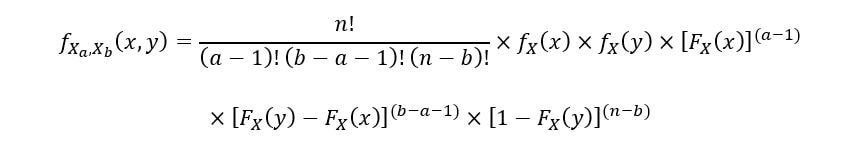
Order Statistics | What is Order Statistics | Introduction to Order Statistics (analyticsvidhya.com)
10_R. Distributions of the order statistics: look on the web for the most simple (but still rigorous) and clear derivations of the distributions, explaining in your own words the methods used.
11_R. Do a research about the general correlation coefficient for ranks and the most common indices that can be derived by it. Do one example of computation of these correlation coefficients for ranks.
10_A. Given a random variable, extract m samples of size n and plot the empirical distribution of its mean (histogram), the first and the last order statistics. Comment on what you see.
11_A. Discover a new important stochastic process by yourself! Consider the general scheme we have used so far to simulate some stochastic processes (such as the relative frequency of success in a sequence of trials, the sample mean and the random walk) and now add this new process to our process simulator.
Same scheme as previous program (random walk), except changing the way to compute the values of the paths at each time. Starting from value 0 at time 0, for each of m paths, at each new time compute N(i) = N(i-1) + Random step(i), for i = 1, …, n, where Random step(i) is now a Bernoulli random variable with success probability equal to λ * (1/n) (where λ is a user parameter, eg. 50, 100, …).
At time n (last time) and one (or more) other chosen inner time 1
Represent also the distributions of the following quantities (and any other quantity that you think of interest):
– Distance (time elapsed) of individual jumps from the origin
– Distance (time elapsed) between consecutive jumps (the so-called “holding times”)
8_RA. Find out on the web what you have just generated in the previous application. Can you find out about all the well known distributions that “naturally arise” in this process ?



![W^{(n)}(t) := \frac{S_{\lfloor nt\rfloor}}{\sqrt{n}}, \qquad t\in [0,1].](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c5b96070ae726d73a42ecf4e1da69b3ba4ce1ac)



![W^{(n)}:=(W^{(n)}(t))_{t\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c9bd97748f3aad3545d97aac1342b6bc4ed96fe)
![\mathcal{D}[0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/f52583cc1475b9a987e8ca67473773444b0be01c)

![W:=(W(t))_{t\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1fc2ccf9ee0af262c9746f48cd2cdb5bf3995e17)